【鱼书】2. 数据与flask路由
- Python
- 2018-11-16
- 5热度
- 0评论
2-1 搜索而不是拍照上传
技术的知识放到具体业务中讲解,效果会更好。
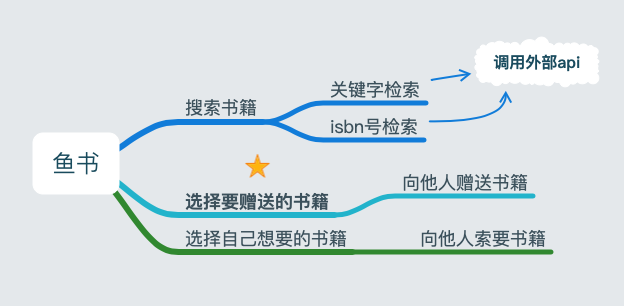
任何一个产品都会从一个最小的原点开始,对于鱼书来说,最小的原点是:“向他人赠送书籍”。
我们最关心的是,“要赠送哪本书”,而不在乎书的新旧程度。所以不需要像闲鱼那样,做拍照上传。那怎么做?直接在网站中搜索关键字或isbn号。
2-2 书籍搜索与查询 1-数据API
搜索的数据从哪里来?依赖外部的数据源。也就是说,需要调用外部的 api 来获取图书检索数据。
关键字搜索:
http://t.yushu.im/v2/book/search?q={}$start={}&count={}
(用 start 和 count 来控制分页)
isbn 搜索:
http://t.yushu.im/v2/book/isbn/{isbn}
可以考虑使用豆瓣的 api
https://api.douban.com/v2/book
没有不控制访问频率的 api,否则很可能几下就被别人搞瘫痪了。
2-3 书籍搜索与查询 2-搜索关键字
外部api需要什么参数?
- q,关键字
- start
- count
- isbn
可以不区分关键字和 isbn(代码里判断),start 和 count 也可以合并。因此,我们需要用户传递的参数为:
- q,普通关键字 isbn
- page
isbn 分类
- isbn13,13个0到9的数字组成
- isbn10,10个0到9的数字,含有一些 ’-’
新书都是 isbn13。
核心代码:
@app.route('/book/search/<q>/<page>')
def search(q, page):
"""
q : 普通关键字 isbn
page
"""
isbn_or_key = 'key'
if len(q) == 13 and q.isdigit():
isbn_or_key = 'isbn'
short_q = q.replace('-', '')
if '-' in q and len(short_q) == 10 and short_q.isdigit():
isbn_or_key = 'isbn'
pass
2-4 书籍搜索与查询 3-简单的重构
刚才写的“判断是 isbn 还是 key”的代码,至少有以下问题:
- 判断代码只是 search 流程中很小的一部分,却占用了 6 行代码的空间。假如继续写下去,这个 search 函数会非常大;
- 无法复用。这段代码只能给 search 使用,其他地方无法使用;
- 从代码阅读者的角度,一眼看不出来这段代码是干嘛的。(过多的注释并不好)
将这段代码提取到 helper.py 中。
简化之后:
@app.route('/book/search/<q>/<page>')
def search(q, page):
"""
q : 普通关键字 isbn
page
:return:
"""
isbn_or_key = is_isbn_or_key(q)
pass
一定要保证视图函数中的代码是简洁、易读的。
如何阅读源代码:不要急于看细节,要自顶向下分层地去看。第一遍的目的:理清楚整个源代码的结构和它线性的线索,而不是关注细节。
2-5 获取书籍数据:调用鱼书API
将 http 相关的方法封装到一个 HTTP 类中(名字不要叫 http.py,与系统库有冲突)。
调用 api 的时候,不仅要考虑有数据情况,还要考虑没有数据的情况。
import requests
class HTTP:
def get(self, url, return_json=True):
r = requests.get(url)
if r.status_code != 200:
return {} if return_json else ''
return r.json() if return_json else r.text
绝大部分开放 api,都符合 restful 标准。
2-6 requests vs urllib
完成同样的功能,urllib 的写法:
@staticmethod
def get_with_request(url, json_return=True):
url = quote(url, safe='/:?=&')
try:
with request.urlopen(url) as r:
result_str = r.read()
result_str = str(result_str, encoding='utf-8')
if json_return:
return json.loads(result_str)
else:
return result_str
except OSError as e:
# 对于外部的数据,如果出现异常,最好不要抛出来,而是应该默认值处理
print(e)
if json_return:
return {}
else:
return None
爬虫:
- Scrapy 框架(大型爬虫,适合并发场景)
- requests + beautiful soap
@staticmethod 和 @classmethod:静态方法、类方法。没有用到类变量(cls),只要作为静态方法就行了。
经典类和新式类。Python3 中都是新式类。
2-7 从 API 获取数据
业务逻辑不要写到视图函数中,封装为 YuShuBook。
class YuShuBook:
isbn_url = 'http://t.yushu.im/v2/book/isbn/{}'
keyword_url = 'http://t.yushu.im/v2/book/search?q={}$start={}&count={}'
@classmethod
def search_by_isbn(cls, isbn):
url = cls.isbn_url.format(isbn)
result = HTTP.get(url)
#dict
return result
@classmethod
def search_by_keyword(cls, keyword, count=15, start=0):
url = cls.keyword_url.format(keyword, start, count)
result = HTTP.get(url)
return result
视图函数:
@app.route('/book/search/<q>/<page>')
def search(q, page):
"""
q : 普通关键字 isbn
page
"""
isbn_or_key = is_isbn_or_key(q)
if isbn_or_key == 'isbn':
result = YuShuBook.search_by_isbn(q)
else:
result = YuShuBook.search_by_keyword(q)
return json.dumps(result), 200, {'content-type':'application/json'}
2-8 使用 jsonify
用 flask 的 jsonify 简化刚才的return 语句。
return jsonify(result)
# return json.dumps(result), 200, {'content-type':'application/json'}
Api:把数据用 json 格式返回到客户端。
开发 Api 的难点在于路由的设计,而不在于如何用技术去实现。
2-9 将视图函数拆分到单独的文件中
现在我们视图函数直接放在 fisher.py 下,但是当视图函数变多的时候,还是放在这个文件中吗?不推荐。
- 代码太长、函数太多,不好维护。
- 不同的业务模型,应该分配到不同的文件中去。
- 入口文件的意义比较独特,它会做很多初始化工作(如服务器启动、初始化 Flask 核心对象),不应该把业务的视图函数放到入口文件里。
将视图函数转移到 book.py 中。
这样会遇到一个问题,app 对象在 fisher.py 中创建,如何在 book.py 中给 app 注册路由?直接 import 一下,为什么不行?
2-10 深入了解 flask 路由
Endpoint 的作用:根据视图函数,反向构造 url。
url->endpoint->view_func
2-11 循环引用流程分析
book.py
from flask import jsonify
from helper import is_isbn_or_key
from yushu_book import YuShuBook
from fisher import app
@app.route('/book/search/<q>/<page>')
def search(q, page):
"""
q : 普通关键字 isbn
page
"""
isbn_or_key = is_isbn_or_key(q)
if isbn_or_key == 'isbn':
result = YuShuBook.search_by_isbn(q)
else:
result = YuShuBook.search_by_keyword(q)
return jsonify(result)
fisher.py
from flask import Flask
app = Flask(__name__)
app.config.from_object('config')
from app.web import book
if __name__ == '__main__':
# 生产环境 nginx+uwsgi 下,以下代码不会执行
app.run(host='0.0.0.0', debug=app.config['DEBUG'], port=8081)
Flask 核心对象初始化了两次,我们用来注册路由的 app,和最终启动的 app,不是同一个 app。
如何查看 app 的内存地址?id(app)。通过 print(id(app)),可以验证刚才的说法。
那么,如何解决这个问题?看下一章:蓝图。
