
精选
2026-07-2910 分钟
从马尔科夫毯看人的命运
洞察命运,改变命运
微服务改造 · DDD · 高并发设计
▸主导核心系统微服务化重构,关键模块性能提升 100 倍,技术债 -80%
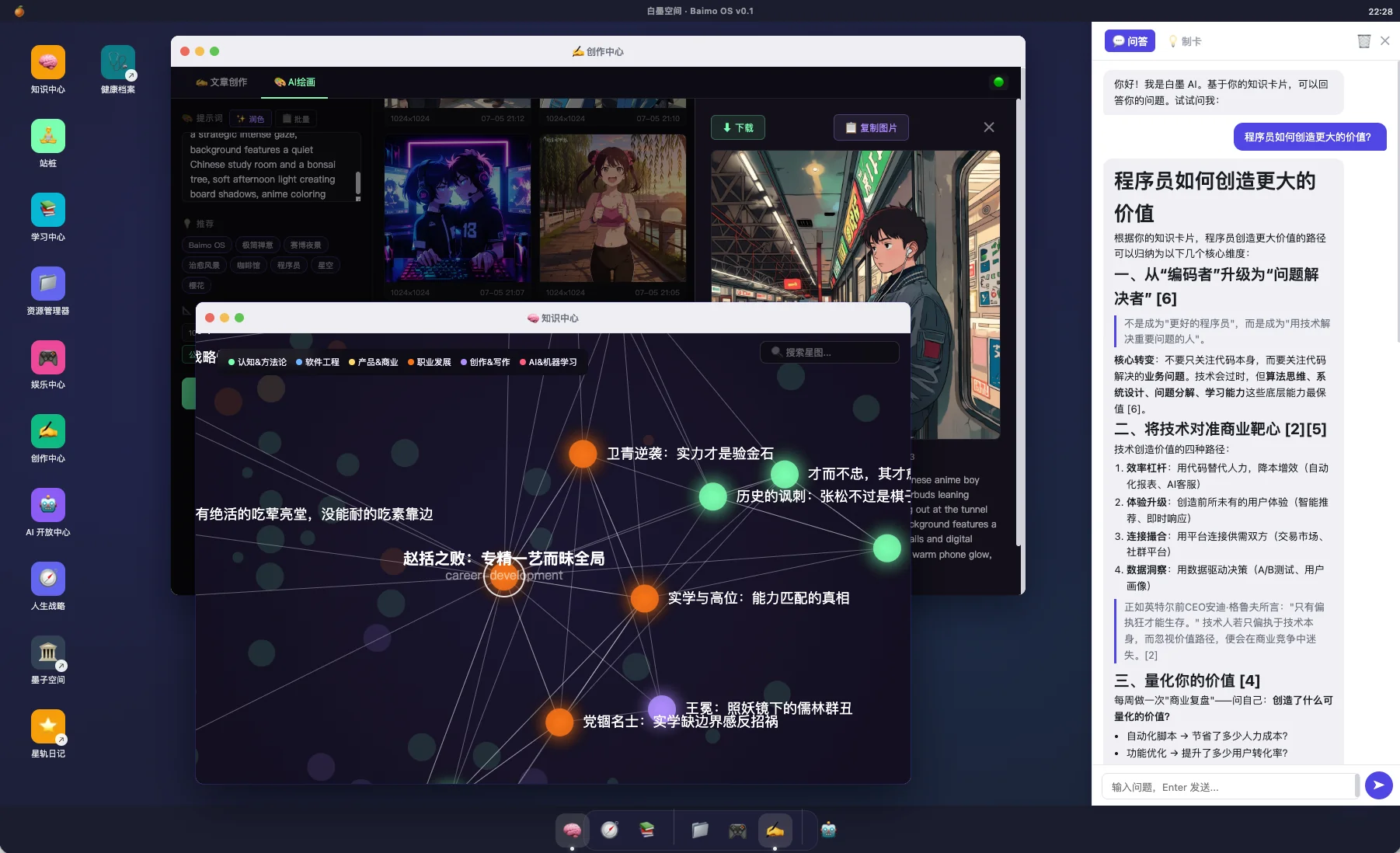
Agent 平台 · RAG · Workflow · 小模型
▸灵枢 OS 一人全链路打造,分钟级创建新 Agent
Flink · Kafka · StarRocks · ClickHouse
▸亿级广告实时数仓 + 自研中间件,单节点千级 QPS
Java 21 · React · TS · 虚拟线程
▸7+ 个 0→1 项目,一人独立交付完整系统
真正的能力藏在解决过的问题里。以下项目均来自真实职业经历与独立开发。
Agent 编排 · RAG · MCP 工具 · 多 Agent 协作 · 上下文工程 · Eval 体系
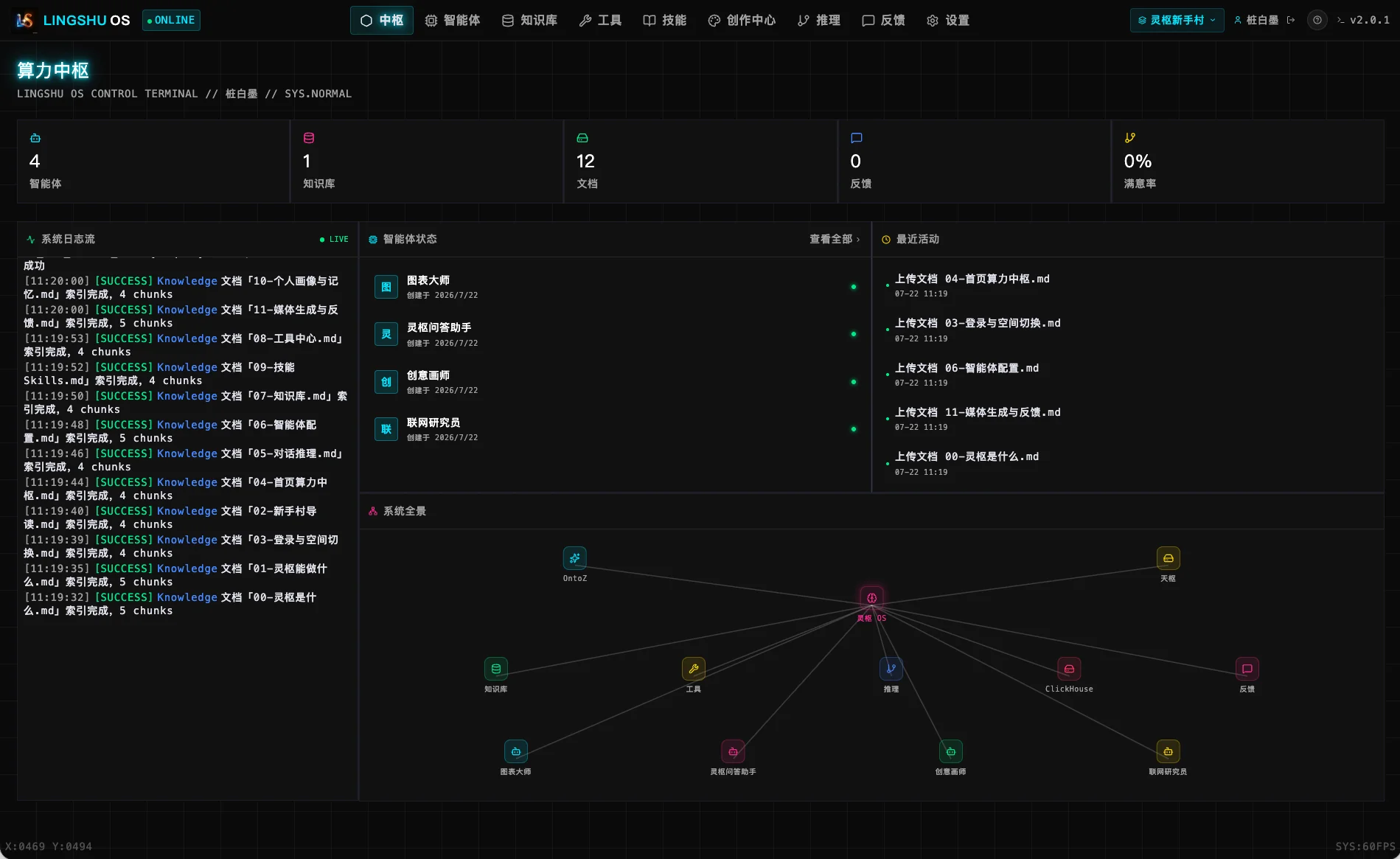
公司核心 Agent 能力平台,承载 AI 原生组织使命。从 idea 到产品、视觉、架构、开发、内部推广,一人全链路完成;业务侧分钟级创建新 Agent。
规划器 · 展会营销 · Google Ads 投流 · AI Workflow
外贸 AI Agent 产品的核心架构与性能攻坚:规划器重构支撑 100 倍用户量,营销查询由分钟级提升至秒级,微服务重构技术债 -80%。
权限中台 · 统一入口 · HR / CRM / 运营中心 · Spring AI
主动提出并一人交付的公司唯一内部系统与统一入口:权限中台、HR、CRM、运营中心等全部业务流程,模块化可无限扩展。与灵枢 OS 互为底座、相互打通。
Kappa 纯流式 · Flink · StarRocks · 微服务
从 0 到 1 引入 Flink 构建亿级广告投流实时数仓,自研 StarRocksSource / StarRocksRepo 两个中间件,以 SQL 为核心的同步框架让同类任务从 2 天缩短到 2 小时。
公安大数据 · Flink · ClickHouse · 实时预警
为警方开发的车辆/人像大数据平台,包含实时预警、离线预警、在线查询三大模块。主导 Flink 实时流的亿级高压稳定性优化,内存从百 G 降至 20G。
左侧是思考随笔,右侧是技术笔记。两种模式,同一种认真。
洞察命运,改变命运

AI 时代,我对工程师自我价值的思考

我对于黑客精神的理解和践行
程序员真正的核心品质,并非技术本身,而是源于好奇与创造乐趣的“折腾精神”。乔布斯的蓝盒子、Linus Torvalds 的 Linux、甚至 Unix 的雏形,都始于“just for fun”的玩心。保持这份偏执与热情,才能在代码中找到生机。
知识不再稀缺,稀缺的是筛选、调用和再生的能力,通过多级索引、缓存高频和输出创造,让知识为我所用,而非为其所累。
软件的生命力在于持续迭代,一旦停止更新便如同死水般僵化。这个规律同样适用于人:固步自封、拒绝成长会让自己陷入停滞与僵死,只有持续学习、自我更新,才能让生命保持流动,始终活着。
学技术不应只为技术本身,而在于学以致用,便利生活和提升效率。
【作者】陈寿 【朝代】魏晋 亮躬耕陇亩,好为《梁父吟》。身长八尺,每自比于管仲、乐毅,时人莫之许也。惟博陵崔州平、颍川徐庶元直与亮友善,谓为信然。 时先主屯新野。徐庶见先主,先主器之,谓先主曰:“诸葛孔明者,卧龙也,将军岂愿见之乎?”先主曰:“君与俱来。”庶曰:“此人可就见,不可屈致也。将军宜枉驾顾之。” 由是先主遂诣…
最近这次跳槽,对我来说意义重大,第一次来到了“大厂”。 分享几点感受: 技术基础很重要 老实说,我的技术底子不够扎实。面试时,表现在八股文较弱;工作时,表现在某些特定技术点的缺失,对技术名词背后的组件、框架理解过于肤浅,技术选型讨论不够用,做大的架构设计显得吃力。 Spring 全家桶,是 Java 的基础。大数据领域…
从股市浮盈到人生经验,缺少沉淀的努力只是一场空。写文章能把飘忽的念头变成扎实的积累,让日子不再白白流过。
1. 现象
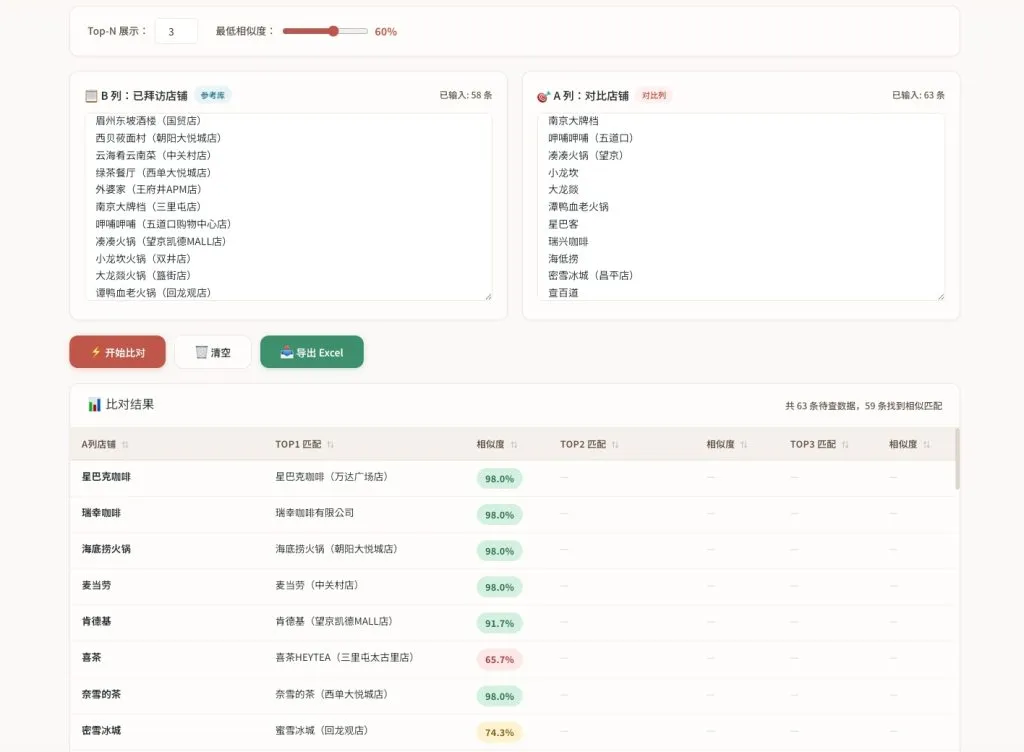
本文通过纯 JavaScript 实现店铺名称相似度比对工具,结合 Levenshtein、Bigram Dice 和 Jaro-Winkler 算法加权组合,并解决括号陷阱、缩写误杀、错别字淹没等真实数据挑战。
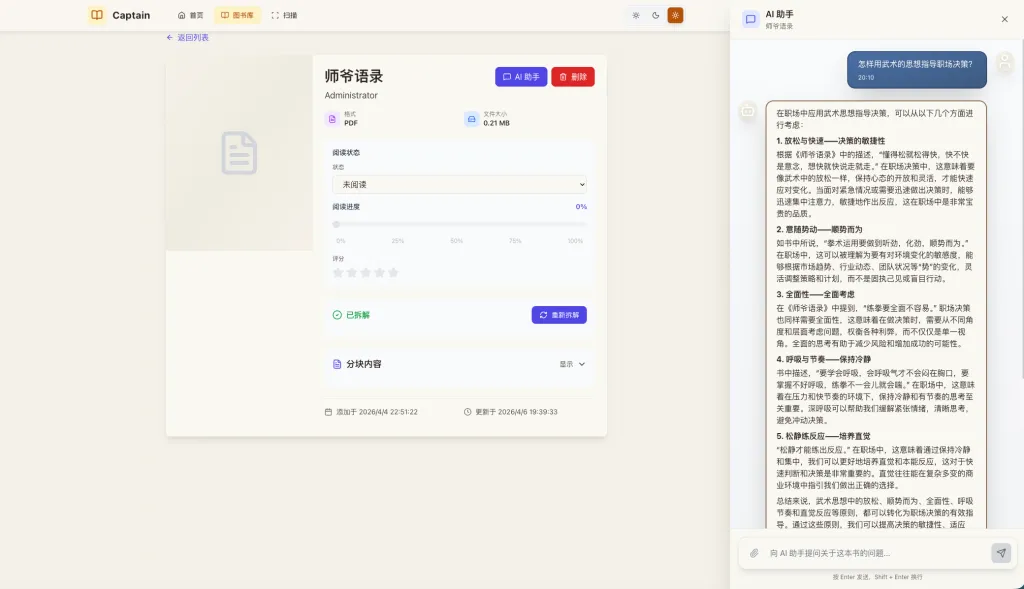
清明假期,我开发了一款私人 AI 图书管理系统,能自动扫描电子书并基于 RAG 技术进行深度拆解,实现与书籍的智能对话。该项目既为深化技术理解,也为高效阅读提供帮助,未来可能开源或创业。

本文探讨了软件模块化设计的概念与价值,介绍了模块划分原则、分层架构等设计思路,并分析了模块粒度、灵活性、胶合层等关键设计权衡,帮助开发者构建清晰、可维护的复杂系统。
本文摘录自《UNIX 编程艺术》,系统阐述了 UNIX 哲学的 17 条设计原则,包括模块、清晰、组合、分离、简洁等核心理念,并深入解读了各原则的内涵与实践态度,是软件开发者的经典参考。
Java 后端有一个在 90% 场景下好用的惯例:把请求级上下文(用户 ID、租户 ID、trace ID)塞进 ThreadLocal,在请求入口 set,在请求出口 clear。Spring 的 RequestContextHolder
多 Agent 协作中最常见的两个问题是"子 Agent 死了我却不知道"和"我说完就走了,没法等结果"——前者让主 Agent 空等超时,后者让本来能在一轮里完成的任务被迫拆分到多轮(用户体验下降、延迟加倍)。
"Agent Loop"(智能体推理循环)是所有 Agent 系统的心脏。这篇文章讲清楚三件事:Agent Loop 到底是什么;我们的内部 Agent 平台里两套 Loop 实现分别长什么样(主 Agent 委托给框架、子 Agent 手
让一个 Agent "记住"用户,最朴素的方案是开一个设置页让用户手填:"我是做外贸的""主要客户在德国"。我们的内部 Agent 平台一开始就是这么做的。但上线后很快发现三个问题:
多 Agent 系统最脆弱的一环不是 LLM——是消息。主 Agent 发一条"请帮我调研中国市场"给子 Agent,子 Agent 没收到,或者收到后崩溃了,或者处理完了但主 Agent 不知道。这些失败模式在没有持久化信箱的系统里是不可
自我沉淀,帮助他人。
面向 Java 工程师的 Agent 开发课:从 ChatClient 到工具调用、记忆、RAG、流式、Advisor 链,直至自主循环 Agent,层层递进。
代码之外:闪过的念头、言志的诗、看过的风景。
随着等级提升,升级旧技能,学习新技能,更新装备,接受新任务,开启新地图。人生如游戏。
Python 本来是一门比较简单,功能稍弱的语言。但它的厉害之处在于:拥有数不清的代码库,结合各种命令行工具,嵌入主流“巨无霸”语言,几乎跨所有平台。号为“胶水”,独步天下。上善。
有一种人,在这俗世,过着武侠生活。任侠,不是一种特定的技能或身份,而是一种可以渗透到任何领域的精神。
忽然想到一个绝妙的比喻:没有热情的工作,就像没有爱情的婚姻。
桩,缘起站桩。桩者,根基也——向下扎根,方能向上生长。
白墨,一白一墨,恰如阴阳太极;亦让我想起偶像王冕的那首《墨梅》——
"我家洗砚池头树,朵朵花开淡墨痕。
不要人夸好颜色,只留清气满乾坤。"
求学时痴迷于各类学习方法,身体力行。学习者无惧。
东南大学软件工程毕业,历经小中大厂 + 初创,十年一线开发经验。
个人提效数十倍,推动 AI 编程在工程团队落地;近 2 年 Agent 产品开发经验。
运营公众号「桩白墨」,6w+ 读者;写读书、成长与思考。
入坑传统健身十年有余,东南大学梅花桩武术协会会长,练过形意拳,去过武当山。
学习者无惧
人一能之,己百之;人十能之,己千之
履霜坚冰至
这里是我的数字自留地,沉淀知识与思考。2014 年 6 月写下第一篇博客,迄今已有十余年。
本站本身也是一件作品:React 19 + Vite 打造,预渲染为纯静态页面;内容以 Markdown 书写、Git 管理,由我与 AI 结对构建,持续生长。
输入关键词搜索本站全部文章
