
导航
一、总论
耦合:也称块间联系。指软件系统结构中各模块间相互联系紧密程度的一种度量。模块之间联系越紧密,其耦合性就越强,模块的独立性则越差。
内聚:又称块内联系。指模块的功能强度的度量,即一个模块内部各个元素彼此结合的紧密程度的度量。当一个类或者模块被设计成只支持一组相关的功能时,我们说它具有高内聚;反之,当被设计成支持一组不相关的功能时,我们说它具有低内聚。
软件设计中通常用耦合度和内聚度作为衡量模块独立程度的标准。划分模块的一个准则就是高内聚低耦合。让每个模块,尽可能的独立完成某个特定的子功能。模块与模块之间的接口,尽量的少而简单。如果某两个模块间的关系比较复杂的话,最好首先考虑进一步的模块划分。
番外:模块的理解
模块是一个相对概念。可以指方法、类、包、多个包形成的功能组(比如我们的 core 包、report 包)……而且不只存在于软件开发中,只要指定一个系统作为参照物,就可以进行模块划分。
二、独立有什么好处?应对变化,早点下班
以下是一个真实世界中,符合“高内聚低耦合”原则的模块划分例子:
间谍、反政府人员、革命者等,常常会组成小组,称为“cell”(最小组织单位,即模块)。尽管每个最小组织单位的人员可能相互认识(高内聚),但他们却不认识其他最小组织单位的人(低耦合)。如果某个最小组织单位被发现了,再多的麻醉药也无法使该组织单位外部的人的姓名泄漏。切断最小组织单位之间的交往能保护每一个人。
把代码组织成最小组织单位(模块),并限制它们之间的交互,至少有以下好处:
- 方便理解和维护。模块越独立、越简单,越容易理解。如果随后必须替换某个模块,其他模块不用修改,仍能够继续工作。bug修复、实现方式重构、需求变更、功能扩展等情况,都需要我们去修改模块中的代码。如果耦合过高,就会牵一发而动全身,改一个小地方引起一大堆问题;如果内聚过低,就会让模块难以理解,难以维护;这些都是导致加班的原因。
- 方便复用。一个设计良好的功能模块,可以轻易地被多个系统复用,进而减少开发成本。
因此,为了又快又好地完成工作,准时下班,我们进行代码设计时,需要尽可能做到“高内聚低耦合”。
三、三招识别耦合与内聚
第一招:直觉。
第二招:对照附录的度量标准。
第三招:画图。
重点讲一下。当一眼看不出来的时候,最好画一个 uml 类图(假设以类为模块单位)。只有使用图,才能跳出具体的代码,看到整体架构。
从图中的依赖关系线条的密集程度,可以大致看出耦合度;从类的方法名称、数量等,可以大致看出内聚度。
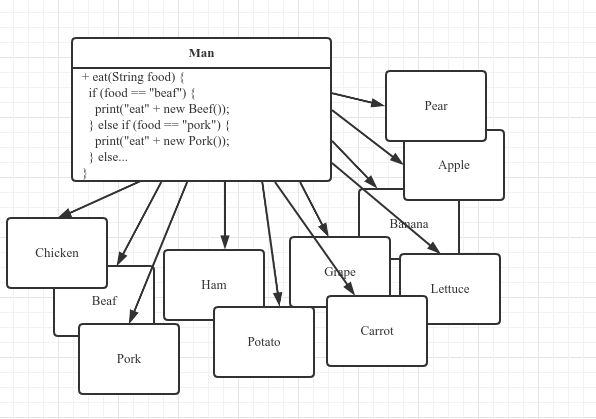
图示高耦合
带实心箭头的黑色实线,表示依赖关系。从图中可以看到,Man 依赖了 11 个对象。如果其中任何一个对象发生了变化(例如类名改了、食用方法变了),都必须同时修改 Man 类。
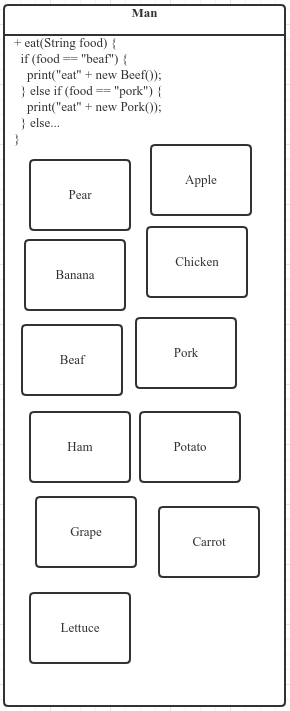
图示低内聚
Man 里有大量不相干的内部类。随着食物类型的增多,Man 类会扩张得越来越大,难以理解和维护。
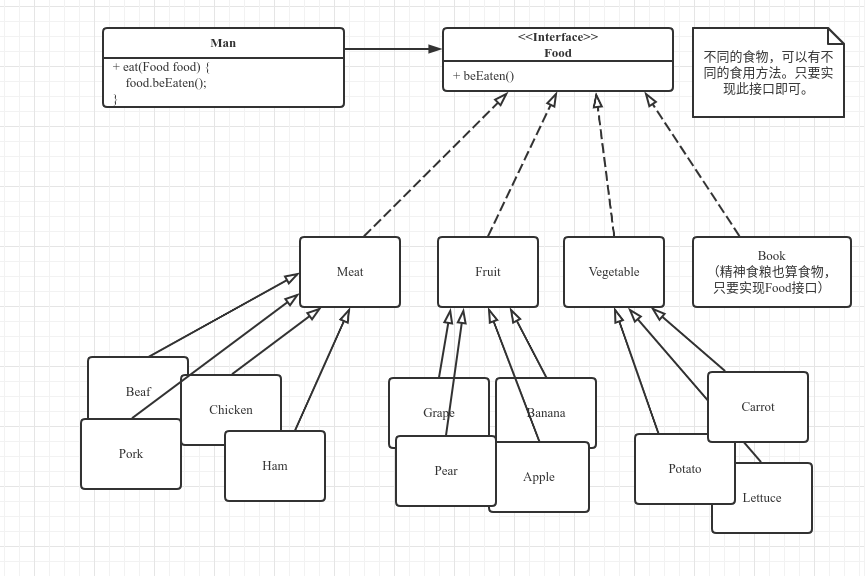
图示低耦合高内聚
经过调整后,Man 类只依赖 Food 接口。(针对接口编程,而不是针对实现编程)
其他实现类也依赖 Food 接口。(依赖倒置原则)
整个系统变得简单、清晰,扩展性也增强了很多。
四、如何做到低耦合高内聚?
轮到设计原则和设计模式上场了。
6大设计原则
- 单一职责原则
- 里氏替换原则
- 依赖倒置原则
- 接口隔离原则
- 迪米特法则
- 开闭原则
再加一条:多用组合,少用继承。
每项原则的具体内容,网上都能找到,不详述。
设计模式
每一个设计模式都是设计原则在某一类场景下的运用,是前人实践经验的总结。我们需要去了解经典的设计模式,并学习如何使用,进而改善自己的架构设计。
附录1 :七种级别的耦合
耦合关系一般有七种,耦合度由低到高:
- 非直接耦合。如果两个模块之间没有直接关系,它们之间的联系完全是通过主模块的控制和调用来实现的,这就是非直接耦合。这种耦合的模块独立性最强。(好莱坞原则)
- 数据耦合。如果一个模块访问另一个模块时,彼此之间是通过数据参数(不是控制参数、公共数据结构或外部变量)来交换输入、输出信息的,则称这种耦合为数据耦合。
- 印记耦合。(我们的 calculator)如果一组模块通过参数表传递记录信息,就是标记耦合。事实上,这组模块共享了这个记录,它是某一数据结构的子结构,而不是简单变量。这要求这些模块都必须清楚该记录的结构,并按结构要求对此记录进行操作。在设计中应尽量避免这种耦合,它使在数据结构上的操作复杂化了。
- 控制耦合。如果一个模块通过传送开关、标志、名字等控制信息,明显地控制选择另一模块的功能,就是控制耦合。这种耦合的实质是在单一接口上选择多功能模块中的某项功能。因此,对所控制模块的任何修改,都会影响控制模块。另外,控制耦合也意味着控制模块必须知道所控制模块内部的一些逻辑关系,这些都会降低模块的独立性。
- 外部耦合。一组模块都访问同一全局简单变量而不是同一全局数据结构,而且不是通过参数表传递该全局变量的信息,则称之为外部耦合。外部耦合引起的问题类似于公共耦合,区别在于在外部耦合中不存在依赖于一个数据结构内部各项的物理安排。
- 公共耦合。若一组模块都访问同一个公共数据环境,则它们之间的耦合就称为公共耦合。公共的数据环境可以是全局数据结构、共享的通信区、内存的公共覆盖区等。 这种耦合会引起下列问题:
- 所有公共耦合模块都与某一个公共数据环境内部各项的物理安排有关,若修改某个数据的大小,将会影响到所有的模块。
- 无法控制各个模块对公共数据的存取,严重影响软件模块的可靠性和适应性。
- 公共数据名的使用,明显降低了程序的可读性。
公共耦合的复杂程度随耦合模块的个数增加而显着增加。若只是两个模块之间有公共数据环境,则公共耦合有两种情况:
1) 松散公共耦合。一个模块只是往公共数据环境里传送数据,而另一个模块只是从公共数据环境中取数据;
2) 紧密公共耦合。两个模块都从公共数据环境中取数据,又都向公共数据环境里送数据。
只有在模块之间共享的数据很多,且通过参数表传递不方便时,才使用公共耦合。否则,还是使用模块独立性比较高的数据耦合好些。
- 内容耦合。如果发生下列情形,两个模块之间就发生了内容耦合。
- 一个模块直接访问另一个模块的内部数据;
- 一个模块不通过正常入口转到另一模块内部;
- 两个模块有一部分程序代码重叠(只可能出现在汇编语言中);
- 一个模块有多个入口。
在内容耦合的情形,所访问模块的任何变更,或者用不同的编译器对它再编译,都会造成程序出错。这种耦合是模块独立性最弱的耦合。
附录2 :七种级别的内聚
内聚关系一般有七种,内聚度由弱到强:
- 偶然内聚。模块中的代码无法定义其不同功能的调用。但它使该模块能执行不同的功能,这种模块称为巧合强度模块。
- 逻辑内聚。这种模块把几种相关的功能组合在一起, 每次被调用时,由传送给模块参数来确定该模块应完成哪一种功能。
- 时间内聚:把需要同时执行的动作组合在一起形成的模块为时间内聚模块。
- 过程内聚:构件或者操作的组合方式是,允许在调用前面的构件或操作之后,马上调用后面的构件或操作,即使两者之间没有数据进行传递。
- 通信内聚:指模块内所有处理元素都在同一个数据结构上操作(有时称之为信息内聚),或者指各处理使用相同的输入数据或者产生相同的输出数据。
- 顺序内聚:指一个模块中各个处理元素都密切相关于同一功能且必须顺序执行,前一功能元素输出就是下一功能元素的输入。即一个模块完成多个功能,这些模块又必须顺序执行。
- 功能内聚:这是最强的内聚,指模块内所有元素共同完成一个功能,联系紧密,缺一不可。
参考文献
- 百度百科,耦合性
- 百度百科,高内聚低耦合
- 百度知道,模块的内聚性有哪几种?各表示什么含义
- 博客园:设计模式——6大设计原则
- 《HeadFirst 设计模式》
- 《程序员修炼之道:从小工到专家》

谢谢分享