
导航
简介
ANTLR(ANother Tool for Language Recognition)是一个强大的解析器生成器,它根据语法定义生成解析器,解析器可以构建和遍历解析树。
所有编程语言的语法,都可以用ANTLR来定义。ANTLR提供了大量的官方 grammar 示例。
核心概念
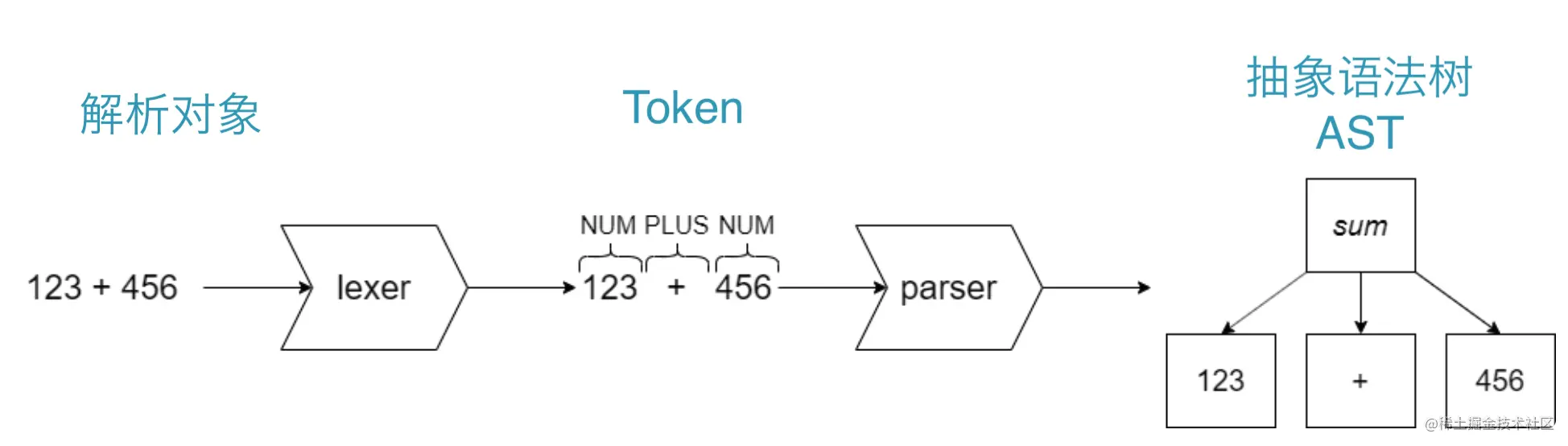
理解三个核心概念:Lexer、Parser、AST。
- 词法分析器(Lexer):将
字符序列转换为单词(Token) - 语法分析器(Parser):将单词(
Token)转换为 AST - 抽象语法树(Abstract Syntax Tree,AST):源代码解析之后形成的树状结构,一般可以用来进行
代码语法的检查,代码风格的检查,代码的格式化,代码的高亮,代码的错误提示以及代码的自动补全等等
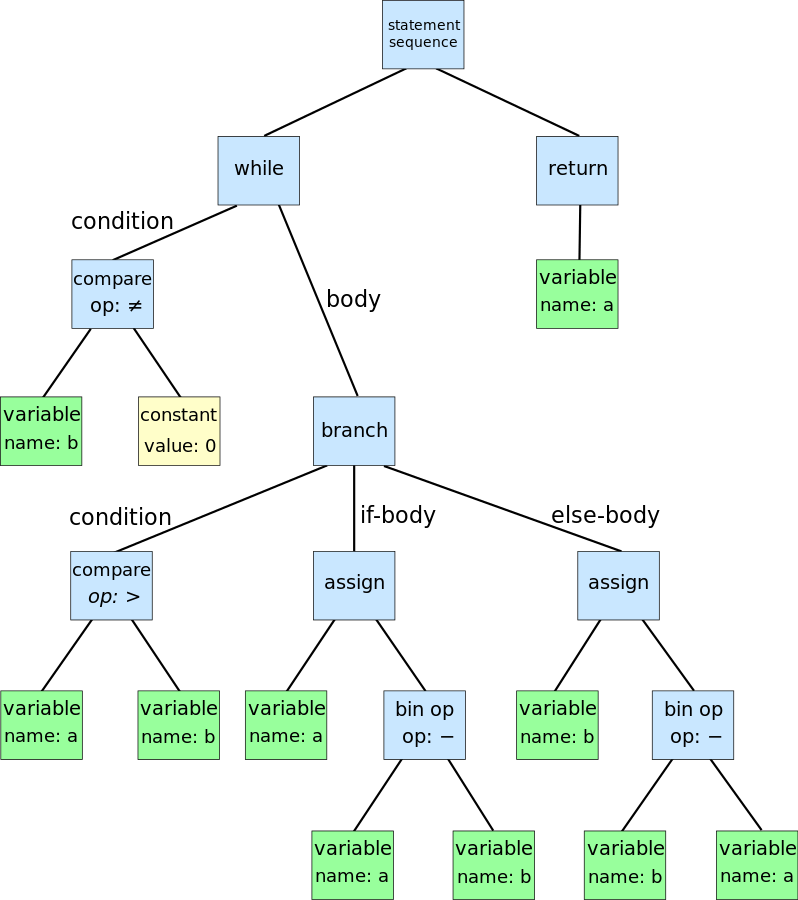
例如,对于以下的代码:
while (b != 0) {
if (a > b) {
a = a - b;
} else {
b = b - a;
}
}
return a;
可以转换为如下的 AST 抽象表达:
使用方法
从实战角度出发,我们直接使用 IDEA,在项目代码中进行操作。跟着我一步步来。
Step1 用 IDEA 创建一个空的 SpringBoot 项目
过程不赘述。
Step2 Maven 配置
引入依赖
<!-- antl4 -->
<dependency>
<groupId>org.antlr</groupId>
<artifactId>antlr4-runtime</artifactId>
<version>4.9.3</version>
</dependency>
加入 ANTLR maven 插件
<plugin>
<groupId>org.antlr</groupId>
<artifactId>antlr4-maven-plugin</artifactId>
<version>4.9.3</version>
<executions>
<execution>
<id>antlr</id>
<goals>
<goal>antlr4</goal>
</goals>
</execution>
</executions>
<configuration>
<arguments>
<argument>-no-listener</argument>
<argument>-visitor</argument>
</arguments>
<treatWarningsAsErrors>true</treatWarningsAsErrors>
</configuration>
</plugin>
Step3 定义语法和词法
需要创建一个.g4文件,用于定义词法分析器(lexer)和语法解析器(Parser)。具体语法参见官方文档。
这个文件要放置到 src/main/antlr4 目录下(这是 maven 插件用的默认位置),然后根据需要的包名创建内层文件夹。
下面是一个简单的例子:Hello.g4。
// file Hello.g4 // Define a grammar called Hello grammar Hello; // 1. grammer name r : 'hello' ID ; // 2. match keyword hello followed by an identifier ID : [a-z]+ ; // match lower-case identifiers WS : [ \t\r\n]+ -> skip ; // 3. skip spaces, tabs, newlines
- 定义了 grammar 的名字,名字需要与文件名对应
r定义的语法,会使用到下方定义的正则表达式词法- 定义了空白字符,后面的 skip 是一个特殊的标记,标记空白字符会被忽略
Step4 生成解析器
执行 maven 的 antlr4 命令,生成解析器代码。生成的结果如图(如果没有识别为源码,需要手动将 antlr4 标记为源码目录):
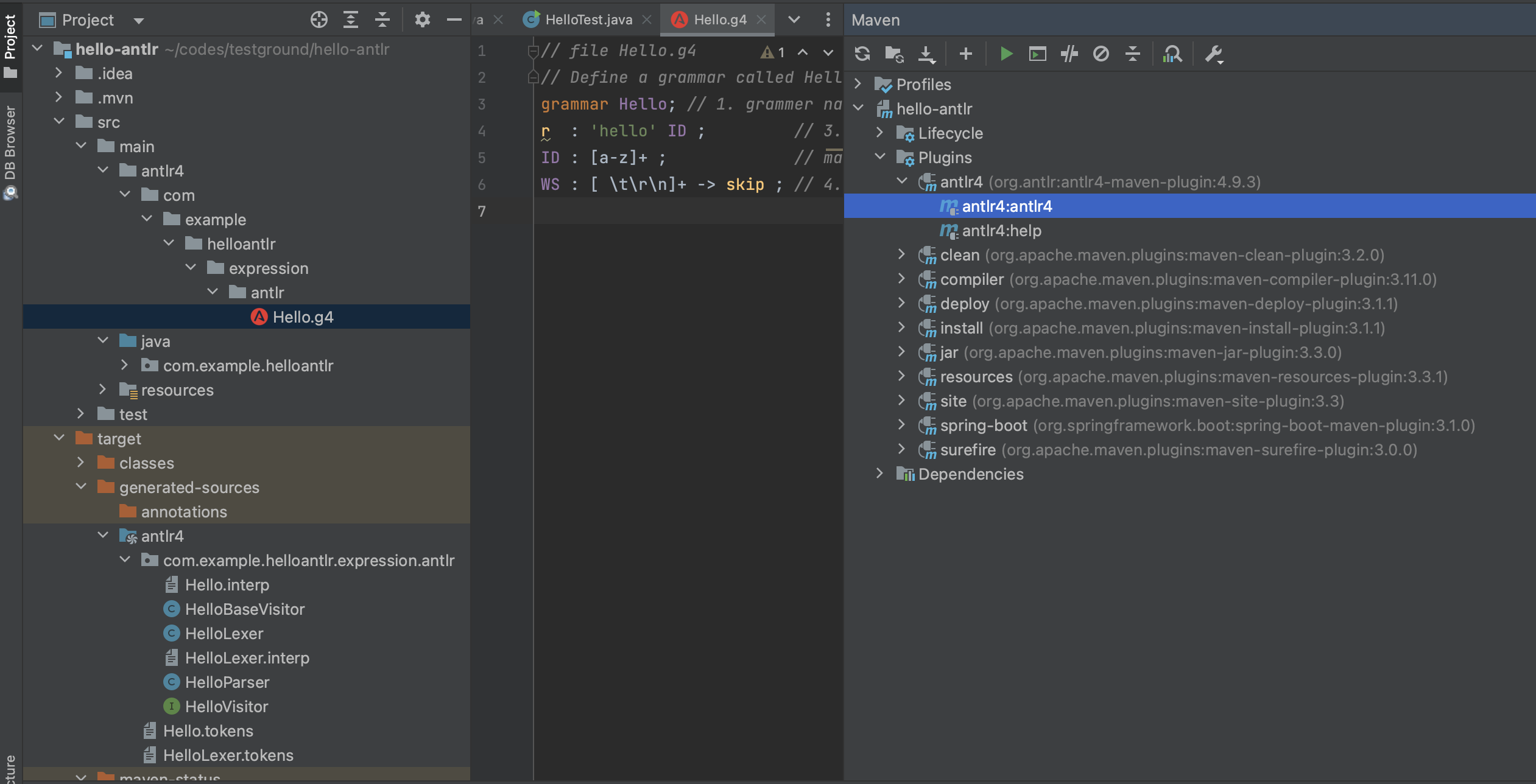
- HelloBaseVisitor.java; // 实现 Visitor 的一个基类 我们业务可以继承这个类来访问 AST 实现自己需要的
- HelloLexer.java; // 词法解析器
- HelloParser.java; // 语法解析器
- HelloVisitor.java // Visitor 用于访问 AST (抽象语法树)
Step5 写一个测试类
public class HelloTest {
public static void main(String[] args) {
HelloLexer lexer = new HelloLexer(CharStreams.fromString("hello part"));
CommonTokenStream tokens = new CommonTokenStream(lexer);
HelloParser parser = new HelloParser(tokens);
ParseTree tree = parser.r();
System.out.println(tree.toStringTree(parser));
}
}
运行后得到输出:
(r hello part)
Step 6 实现 Visitor
ANTLR提供了 Listener 和 Visitor 两种方法来访问 ParseTree。最大的区别是Listener会自动访问 AST 的所有节点,而 Visitor 如果要访问当前节点的子树,则需要手工实现。
Visitor 较为简单方便,继承 HelloBaseVisitor 类即可。
创建一个 Visitor:
public class HelloVisitorImpl extends HelloBaseVisitor<String> {
@Override
public String visitR(HelloParser.RContext ctx) {
return ctx.ID().getText();
}
}
改写 HelloTest 的代码,加上 Visitor 调用逻辑:
public class HelloTest {
public static void main(String[] args) {
HelloLexer lexer = new HelloLexer(CharStreams.fromString("hello part"));
CommonTokenStream tokens = new CommonTokenStream(lexer);
HelloParser parser = new HelloParser(tokens);
ParseTree tree = parser.r();
HelloVisitorImpl visitor = new HelloVisitorImpl();
String ans = visitor.visit(tree);
System.out.println(ans);
}
}
输出的结果是
part
实践 | 做一个计算器
我们来实现一个简单的计算器。
Step1 定义语法和词法
创建 Calculator.g4,内容如下:
// 定义了 grammar 的名字,名字需要与文件名对应
grammar Calculator;
/**
* parser
* calc 和 expr 就是定义的语法,会使用到下方定义的词法
* 注意 # 后面的名字,是可以在后续访问和处理的时候使用的。
* 一个语法有多种规则的时候可以使用 | 来进行配置。
*/
calc
: (expr)* EOF # calculationBlock
;
// 四则运算分为了两个非常相似的语句,这样做的原因是为了实现优先级,乘除是优先级高于加减的。
expr
: BR_OPEN expr BR_CLOSE # expressionWithBr
| sign=(PLUS|MINUS)? num=(NUMBER|PERCENT_NUMBER) # expressionNumeric
| expr op=(TIMES | DIVIDE) expr # expressionTimesOrDivide
| expr op=(PLUS | MINUS) expr # expressionPlusOrMinus
;
/**
* lexer
*/
BR_OPEN: '(';
BR_CLOSE: ')';
PLUS: '+';
MINUS: '-';
TIMES: '*';
DIVIDE: '/';
PERCENT: '%';
POINT: '.';
// 定义百分数
PERCENT_NUMBER
: NUMBER ((' ')? PERCENT)
;
NUMBER
: DIGIT+ ( POINT DIGIT+ )?
;
DIGIT
: [0-9]+
;
// 定义了空白字符,后面的 skip 是一个特殊的标记,标记空白字符会被忽略
SPACE
: ' ' -> skip
;
Step2 实现 Visitor
生成解析器代码之后,我们来实现 Visitor,支持 BigDecimal。BigDecimalCalculationVisitor,内容如下:
public class BigDecimalCalculationVisitor extends CalculatorBaseVisitor<BigDecimal> {
/**
* 100
*/
private static final BigDecimal HUNDRED = BigDecimal.valueOf(100);
/**
* DECIMAL128のMathContext (桁数34、RoundingMode.HALF_EVEN)
*/
private static final MathContext MATH_CONTEXT = MathContext.DECIMAL128;
@Override
public BigDecimal visitCalculationBlock(CalculatorParser.CalculationBlockContext ctx) {
BigDecimal calcResult = null;
for (CalculatorParser.ExprContext expr : ctx.expr()) {
calcResult = visit(expr);
}
return calcResult;
}
@Override
public BigDecimal visitExpressionTimesOrDivide(CalculatorParser.ExpressionTimesOrDivideContext ctx) {
BigDecimal left = visit(ctx.expr(0));
BigDecimal right = visit(ctx.expr(1));
switch (ctx.op.getType()) {
case CalculatorLexer.TIMES: return left.multiply(right, MATH_CONTEXT);
case CalculatorLexer.DIVIDE: return left.divide(right, MATH_CONTEXT);
default: throw new RuntimeException("unsupported operator type");
}
}
@Override
public BigDecimal visitExpressionPlusOrMinus(CalculatorParser.ExpressionPlusOrMinusContext ctx) {
BigDecimal left = visit(ctx.expr(0));
BigDecimal right = visit(ctx.expr(1));
switch (ctx.op.getType()) {
case CalculatorLexer.PLUS: return left.add(right, MATH_CONTEXT);
case CalculatorLexer.MINUS: return left.subtract(right, MATH_CONTEXT);
default: throw new RuntimeException("unsupported operator type");
}
}
@Override
public BigDecimal visitExpressionWithBr(CalculatorParser.ExpressionWithBrContext ctx) {
return visit(ctx.expr());
}
@Override
public BigDecimal visitExpressionNumeric(CalculatorParser.ExpressionNumericContext ctx) {
BigDecimal numeric = numberOrPercent(ctx.num);
if (Objects.nonNull(ctx.sign) && ctx.sign.getType() == CalculatorLexer.MINUS) {
return numeric.negate();
}
return numeric;
}
private BigDecimal numberOrPercent(Token num) {
String numberStr = num.getText();
switch (num.getType()) {
case CalculatorLexer.NUMBER: return decimal(numberStr);
case CalculatorLexer.PERCENT_NUMBER: return decimal(numberStr.substring(0, numberStr.length() - 1).trim()).divide(HUNDRED, MATH_CONTEXT);
default: throw new RuntimeException("unsupported number type");
}
}
private BigDecimal decimal(String decimalStr) {
return new BigDecimal(decimalStr);
}
}
Step3 业务类中调用解析器
public class Calculator {
public BigDecimal execute(String expression) {
CharStream cs = CharStreams.fromString(expression);
CalculatorLexer lexer = new CalculatorLexer(cs);
CommonTokenStream tokens = new CommonTokenStream(lexer);
CalculatorParser parser = new CalculatorParser(tokens);
CalculatorParser.CalcContext context = parser.calc();
BigDecimalCalculationVisitor visitor = new BigDecimalCalculationVisitor();
return visitor.visit(context);
}
}
Step4 测试用例
class CalculatorTest {
private final Calculator calculator = new Calculator();
@DisplayName("Test Calculator")
@ParameterizedTest
@CsvSource({
"1 + 2, 3",
"3 - 2, 1",
"2 * 3, 6",
"6 / 3, 2",
"6 / (1 + 2) , 2",
"50%, 0.5",
"100 * 30%, 30.0"
})
void testCalculation(String expression, String expected) {
assertEquals(expected, calculator.execute(expression).toPlainString());
}
}

