
导航
一个”粘贴数据 → 一键比对”的小工具背后的算法与工程思考。
一、问题的起点
前段时间做了一个小工具,需求很简单:
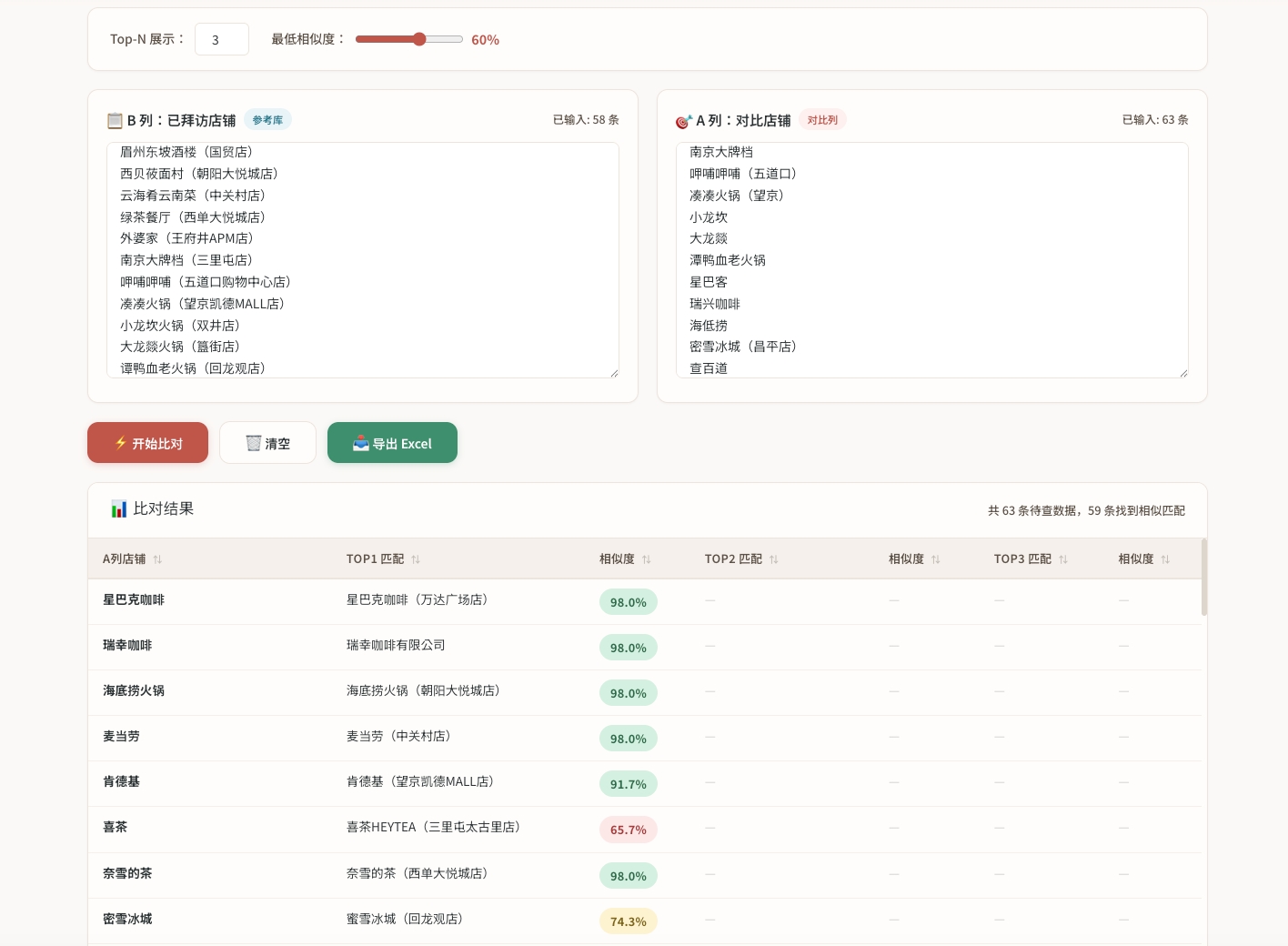
有一张 Excel 表,B 列是已经拜访过的店铺名称(参考库),A 列是打算拜访的店铺名称(待查重)。把两列数据粘贴到工具里,一键识别:A 列每一条,对应 B 列中哪些条目高度相似?相似度是多少?
比如,A 列的”星巴克咖啡”应该匹配到 B 列的”星巴克咖啡(万达广场店)”(相似度 98%),而”沃尔玛”和”星巴克咖啡”应该给出 0%。
初看之下,”相似度”这个词很容易让人联想到 NLP、语义理解、Embedding 向量——甚至大模型。但仔细拆解需求后会发现:这本质上是一个字符串相似度问题,不是语义理解问题。
二、为什么不放大招
做技术选型时,最常见的冲动是”杀鸡用牛刀”。我们来逐一分析为什么这条路走不通,或者说,不值得。
2.1 大模型(LLM)
用 GPT 来做当然可以——把两列数据扔给模型,让它判断哪些是重复的。
问题在哪?
- 延迟:哪怕只做 100 × 50 = 5,000 次比较,每次 API 调用 200ms,总计 16 分钟。如果数据量到 1000 × 500,那就是地狱。
- 成本:5,000 次 API 调用的 token 消耗不小,而字符串算法在浏览器里跑完全免费。
- 确定性:LLM 的输出不稳定。同样的输入问两次,可能第一次给 90%,第二次给 85%。对于”排查重复门店”这种需要精确判断的场景,不确定性是致命的。
- 过度设计:你不需要模型理解”星巴克”是一家咖啡店,你只需要知道”星巴克”和”星巴客”只差一个字。
2.2 Embedding / 向量检索
用 text-embedding 模型把店铺名转成向量,然后算余弦相似度。
问题在哪?
- 短文本灾难:店铺名通常 3-15 个字。在这种长度下,embedding 的质量非常依赖训练数据的覆盖度。大量中小品牌、地方性店铺名根本不在预训练语料里。
- 错别字不敏感:Embedding 模型对字形相近但语义无意义的错字(”星巴客” vs “星巴克“)没有特别的偏好——因为它在训练时学的是语义分布,不是字形相似度。
- 引入外部依赖:需要下载模型或调 API,工具没法做成单 HTML 文件。
2.3 搜索引擎(Elasticsearch / Lucene)
用倒排索引 + fuzzy query。
问题在哪?
- 还是重:Lucene 的 fuzzy query 基于 Damerau-Levenshtein 编辑距离,算法本身和我们用的差不多,但你需要维护一个 Java 服务。
- 调参黑盒:ES 的
fuzziness: AUTO内部逻辑复杂,不同长度的词行为不同,出了问题很难精调。
小结
| 方案 | 延迟 | 成本 | 确定性 | 部署复杂度 | 适合场景 |
|——|——|——|——–|———–|———|
| LLM | 高 | 高 | 差 | 中 | 需要语义理解 |
| Embedding | 中 | 中 | 中 | 高 | 长文本、跨语言 |
| Lucene | 低 | 中 | 好 | 高 | 全文检索 |
| 纯字符串算法 | 极低 | 零 | 完全确定 | 零(单 HTML) | 短文本精确匹配 |
核心洞察:技术选型的第一步,不是问”什么技术能解决这个问题”,而是问”这个问题到底需要解决什么”。 把”语义相似度”还原为”字符串相似度”,方案空间就大大缩小了。
三、三剑客:Levenshtein + Bigram Dice + Jaro-Winkler
单一算法总有自己的盲区。解决方案是三算法加权组合,让它们互相补位。
3.1 Levenshtein 编辑距离 —— 抓错别字
原理:将一个字符串转换成另一个所需的最少编辑操作次数(增、删、改)。归一化为相似度:
similarity = 1 - edit_distance / max(len(a), len(b))擅长:检测单个字符的替换、插入、删除。
"星巴克" vs "星巴客" → 编辑距离 1,相似度 67%
"瑞幸咖啡" vs "瑞兴咖啡" → 编辑距离 1,相似度 75%盲区:当字符串长度悬殊时,编辑距离被额外内容严重稀释。
"华莱士"(3字) vs "华莱士炸鸡汉堡(通州万达店)"(14字)
→ 编辑距离 11,相似度仅 21%明明”华莱士”完整包含在长名中,却只得了 21%。这就需要第二个算法来救场。
3.2 Bigram Dice 系数 —— 抓结构重合
原理:将字符串切分为长度为 2 的字符片段(bigram),计算两个 bigram 集合的 Dice 系数:
Dice(A, B) = 2 × |A ∩ B| / (|A| + |B|)擅长:检测字符串之间的”共用词段”,不太受长度影响。
"全家便利店" vs "全家便利店(中山路店)"
→ 共享 bigram: ["全家","家便","便利","利店"],Dice = 0.67盲区:对顺序不敏感;对单个字符的替换(尤其是中间位置)过于严厉。
"瑞幸咖啡" vs "瑞兴咖啡"
→ bigram: ["瑞幸","幸咖","咖啡"] vs ["瑞兴","兴咖","咖啡"]
→ 仅共享 "咖啡",Dice = 0.33一个字不同,破坏了 2/3 的 bigram。Dice 系数在这里比编辑距离更悲观。
3.3 Jaro-Winkler —— 抓前缀匹配
原理:Jaro 距离衡量两个字符串中匹配字符的比例和换位次数。Winkler 改良版对前缀匹配给予额外加分——前缀越像,分数越高。
擅长:识别”核心名相同,后面多了内容”的场景。这是店铺名中最常见的模式。
"海底捞火锅" vs "海底捞火锅(朝阳大悦城店)"
→ 前 5 个字符完全相同,Winkler 前缀加分显著
→ JW 相似度 ≈ 88%盲区:对非前缀的错别字敏感度不如编辑距离。
3.4 三合一
最终公式:
score = 0.30 × Levenshtein + 0.30 × BigramDice + 0.40 × JaroWinklerJW 权重最高,因为店铺名的核心模式是”前缀相同 + 后缀不同”。三家各管一摊:
| 算法 | 主要战场 | 权重 |
|——|———|——|
| Levenshtein | 错别字检测 | 30% |
| Bigram Dice | 长文本结构重合 | 30% |
| Jaro-Winkler | 前缀匹配 / 同品牌变体 | 40% |
四、真实世界的三个”坑”
算法搭好只是第一步。真实数据跑起来,问题才开始暴露。
4.1 坑一:括号陷阱
现象:测试数据中,”正新鸡排(回龙观店)” 和 “正新鸡排(昌平店)” 被判定为 100% 相似。
原因:最初的设计是预处理时直接删掉括号及其内容——结果两个名字都变成了”正新鸡排”,完全相同。
问题本质:把数据的格式特征(分店信息放在括号里)当成了无用噪声直接丢弃。但真实数据格式是未知的——可能用括号、可能用短横线、可能用空格、甚至没有分隔符。
解决:格式解耦。不假设数据有括号结构,让算法自己处理差异。两个不同门店的名字共享前缀但后续字符不同——Levenshtein 和 JW 自然会给它们 70-80% 的分数,不会满分。
修复前: "正新鸡排(回龙观店)" vs "正新鸡排(昌平店)" → 100% ❌
修复后: 同对上 → 74.5% 🟡 ✅ (同一品牌不同门店,不应满分)教训:预处理应该只做格式无关的标准化(全角转半角、去空白),不应该假设特定格式并丢弃信息。
4.2 坑二:缩写被误杀
现象:”华莱士”和”华莱士炸鸡汉堡(通州万达店)”只有 56% 相似度。
原因:短名(3 字)和长名(14 字)的长度比 1:4.7。Levenshtein 被大量额外字符惩罚,Bigram 被稀释,只有 JW 给了一些前缀分——但远远不够。
解决:两件事——
- 包含加分:若短名完整包含在长名中,按
√(长度比)曲线加分。用平方根而非线性,确保长度悬殊时也能获得有意义加分。 - 前缀加分:若短名是长名的前缀,额外 +15%。
修复前: 56.3% 🔴
修复后: 91.7% 🟢4.3 坑三:错别字被淹没
现象:”密雪冰城”(错一个字)和”蜜雪冰城(回龙观店)”只得了 46.3%。
原因:错的那一个字(密→蜜)在 Levenshtein 中只占一小部分惩罚,但长名其余 6 个字(城(回龙观店))产生了大量额外编辑距离,把错别字的信号彻底淹没。
解决:前缀片段重算。当检测到长度不等且非包含关系时,在长名的前 N 个字符(N = 短名长度)上重跑三个算法。如果这个”前缀分数”远高于全串分数,说明短名在长名的前缀区域有良好匹配——这就是错别字信号。将前缀分数和全串分数按 65/35 融合。
再加上逐字位置匹配加分:如果两个字符串同位字符的匹配率 ≥ 60%,按比例加 bonus。
修复前: 46.3% 🔴
修复后: 74.3% 🟡五、最终效果
整体分层
| 分数区间 | 含义 | 示例 |
|———|——|——|
| 🟢 85-100% | 高度相似,大概率同一店铺 | 海底捞火锅 vs 海底捞火锅(朝阳店)→ 98% |
| 🟡 70-85% | 中度相似,可能同品牌不同门店或缩写 | 华莱士 vs 华莱士炸鸡汉堡(通州店)→ 92% |
| 🔴 <70% | 低相似,大概率无关 | 沃尔玛 vs 星巴克咖啡 → 0% |
错别字提升
| 案例 | 修复前 | 修复后 |
|——|——–|——–|
| 密雪冰城 → 蜜雪冰城 | 46% 🔴 | 74% 🟡 |
| 便易坊烤鸭 → 便宜坊烤鸭 | 62% 🔴 | 82% 🟡 |
| 潭鸭血火锅 → 谭鸭血火锅 | 65% 🔴 | 87% 🟢 |
六、总结与思考
6.1 算法选择的艺术
这个项目让我再次确认了一个信念:在动手选技术之前,先问”这个问题的本质是什么”。
“比对相似店铺名”听起来很像一个 NLP 任务,但拆开来看:店铺名是短文本(3-20 字),比对的核心是同品牌名下的拼写变体、门店后缀、错别字——全是字形层面的差异。不涉及”星巴克是咖啡店”这类语义知识。
一旦把问题正确定义为”字符串模糊匹配”而非”语义理解”,方案就清晰了:三个经典算法各管一摊,参数在浏览器里就能跑,延迟为零,成本为零,结果完全确定。
6.2 工程化的价值
算法的核心逻辑(三加权组合)写出来不到 20 行。但让它在真实数据上好用的工作量,远大于实现算法本身。
三个坑(括号耦合、缩写误杀、错别字淹没)都不是算法理论的问题,而是算法与真实数据之间的适配问题。解决它们需要的不是更高深的数学,而是:
- 理解数据中真实的变异模式
- 识别算法在哪些边界条件下崩溃
- 设计针对性的补偿策略(前缀重算、包含加分、逐字奖励)
这才是工程的核心竞争力——不是重复造轮子,而是让轮子在真实路面上不翻车。
6.3 简单方案的生命力
整套方案约 200 行 JavaScript,零依赖,单 HTML 文件,双击打开即用。Excel 导出通过 CDN 加载 SheetJS。
相比之下,用大模型需要处理 API key、网络延迟、token 计费、输出不稳定;用向量数据库需要搭服务、维护索引、处理模型更新。在正确的场景选择正确的复杂度,是技术判断力的核心。
